The relative importance of depth cues and semantic edges for indoor mobility using simulated prosthetic vision in immersive virtual reality
Abstract
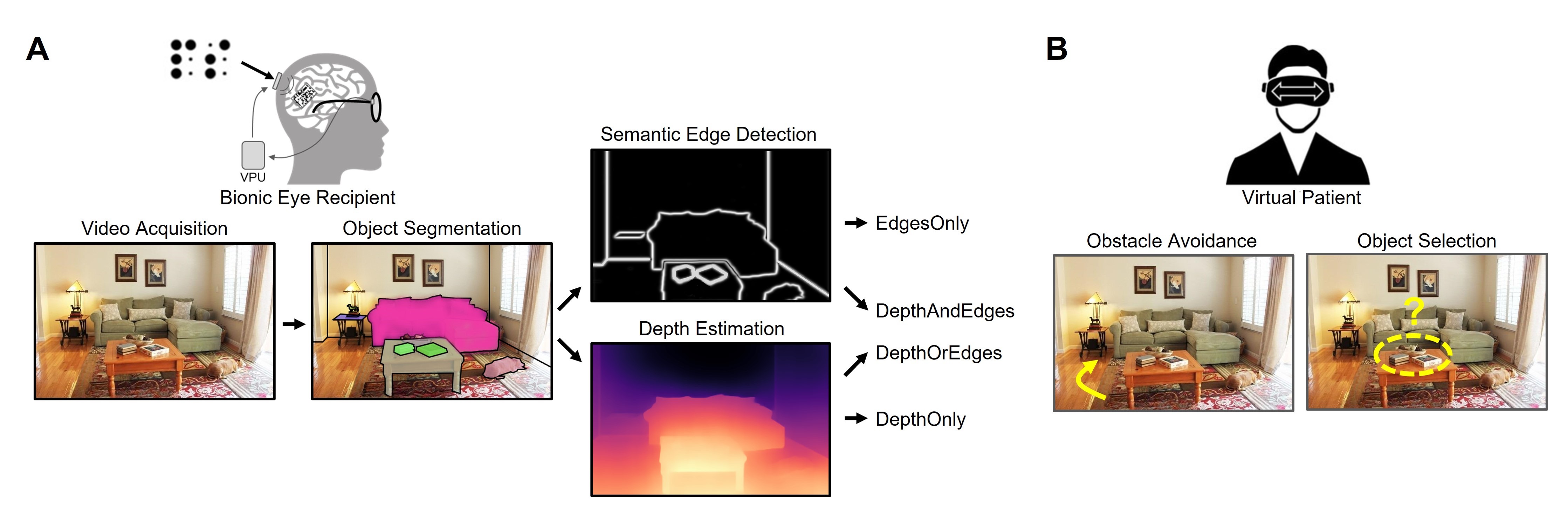
Visual neuroprostheses (bionic eyes) have the potential to treat degenerative eye diseases that often result in low vision or complete blindness. These devices rely on an external camera to capture the visual scene, which is then translated frame-by-frame into an electrical stimulation pattern that is sent to the implant in the eye. To highlight more meaningful information in the scene, recent studies have tested the effectiveness of deep-learning based computer vision techniques, such as depth estimation to highlight nearby obstacles (DepthOnly mode) and semantic edge detection to outline important objects in the scene (EdgesOnly mode). However, nobody has attempted to combine the two, either by presenting them together (EdgesAndDepth) or by giving the user the ability to flexibly switch between them (EdgesOrDepth). Here, we used a neurobiologically inspired model of simulated prosthetic vision (SPV) in an immersive virtual reality (VR) environment to test the relative importance of semantic edges and relative depth cues to support the ability to avoid obstacles and identify objects. We found that participants were significantly better at avoiding obstacles using depth-based cues as opposed to relying on edge information alone, and that roughly half the participants preferred the flexibility to switch between modes (EdgesOrDepth). This study highlights the relative importance of depth cues for SPV mobility and is an important first step towards a visual neuroprosthesis that uses computer vision to improve a user’s scene understanding.
At #SIGCHI #VRST2022? Check out Alex Rasla's talk tonight:https://t.co/ZPh0QpKi2g
— Michael Beyeler (@ProfBeyeler) November 30, 2022
He will be presenting his Master Project on depth and edge based scene simplification for simulated prosthetic vision, for which he won a Gary Marsden Travel Award! 🎉#BionicEye #VirtualReality pic.twitter.com/cUOhuqcpS0